Guy Gaziv

Research Scientist
Meta
NeuroAI researcher at the interface of human and machine vision.
Currently a research scientist at Meta Reality Labs. Previously, a postdoctoral researcher in the DiCarlo Lab at MIT and an affiliate of the Center for Brains, Minds and Machines (CBMM).
I am passionate about harnessing models of primate visual cognition for beneficial neural and behavioral modulation. More broadly, I am fascinated by interdisciplinary research at the intersection of AI, physics, and biology.
My PhD, supervised by Prof. Michal Irani, pioneered methods for decoding visual experience from brain activity.
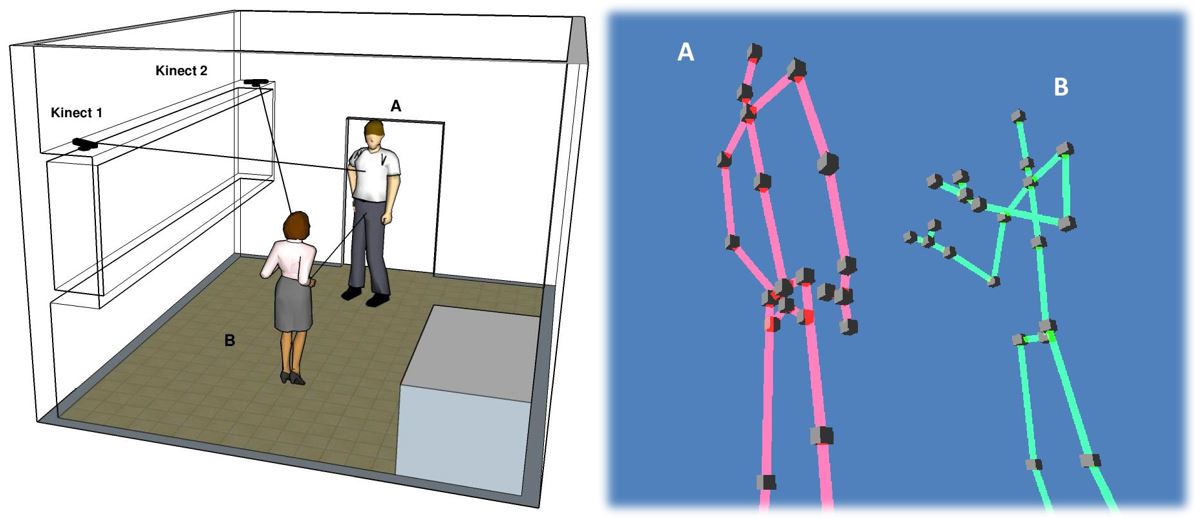
My MSc, advised by Prof. Uri Alon, explored human joint action during natural conversations.
I earned a BSc in Physics-EECS from the Hebrew University of Jerusalem, and an MSc in Physics and a PhD in Computer Science from The Weizmann Institute of Science.
I was honored to be nominated for the Fulbright Postdoctoral Fellowship Award.
News
- 10/2025: Excited to share that I will be joining Meta Reality Labs in NYC as a Research Scientist, building neural interfaces!
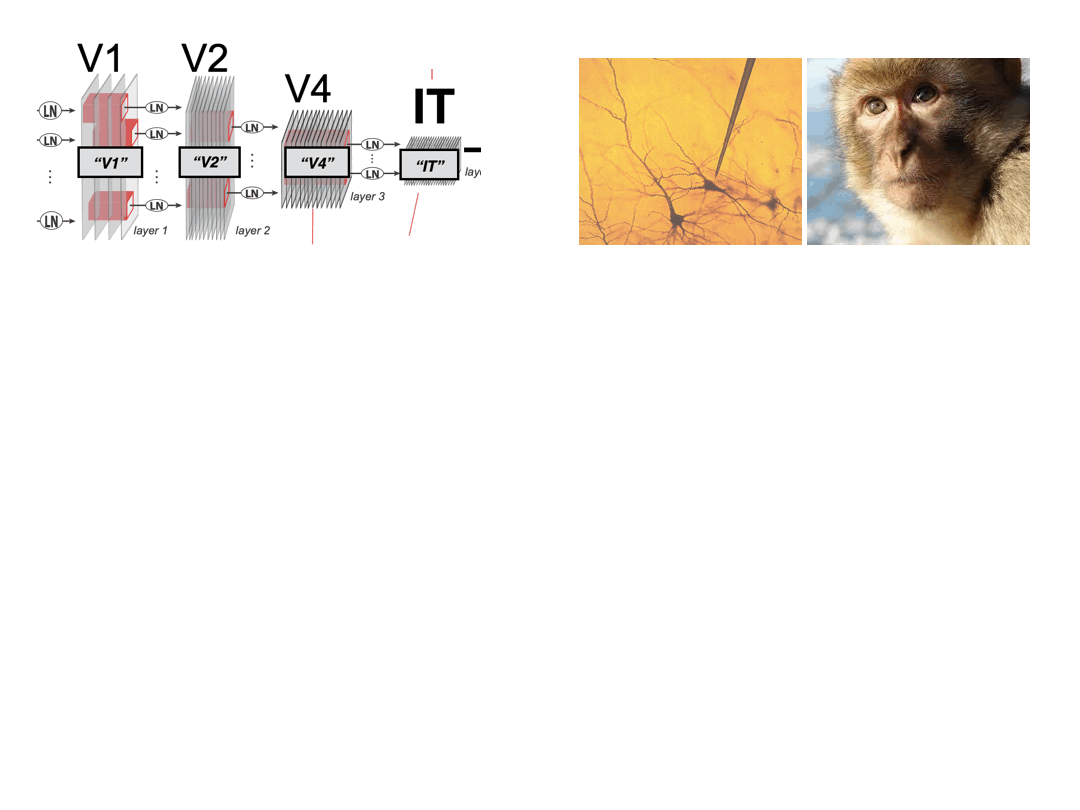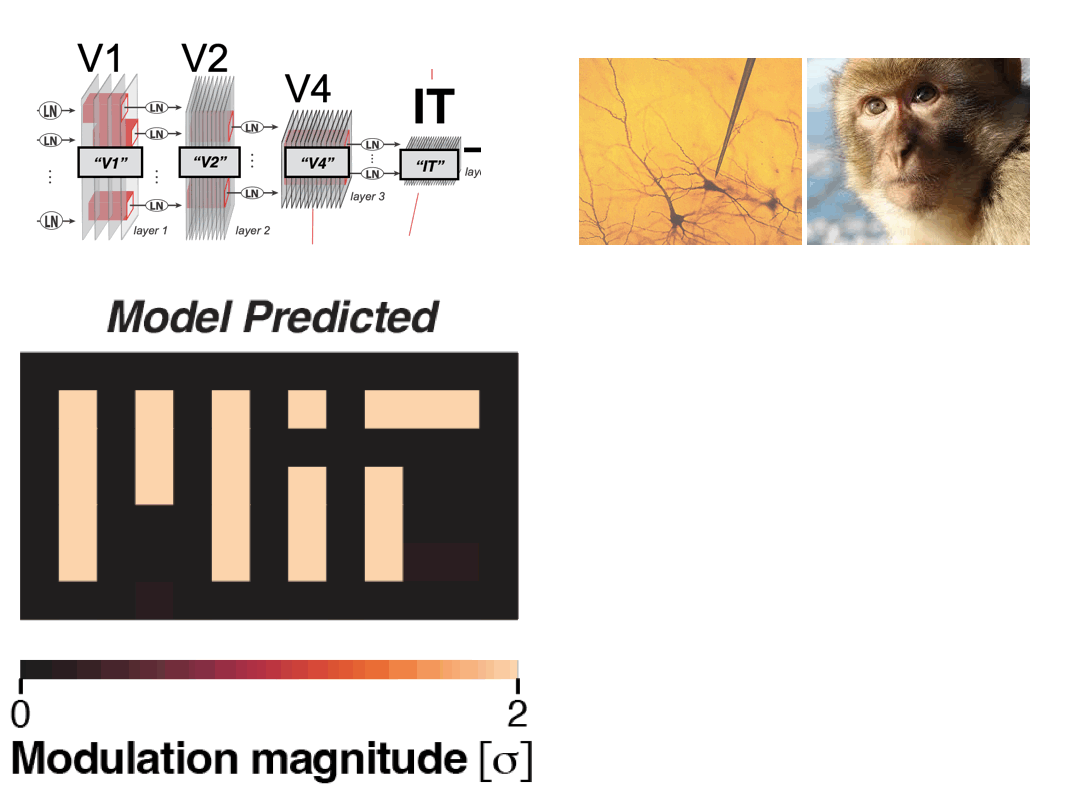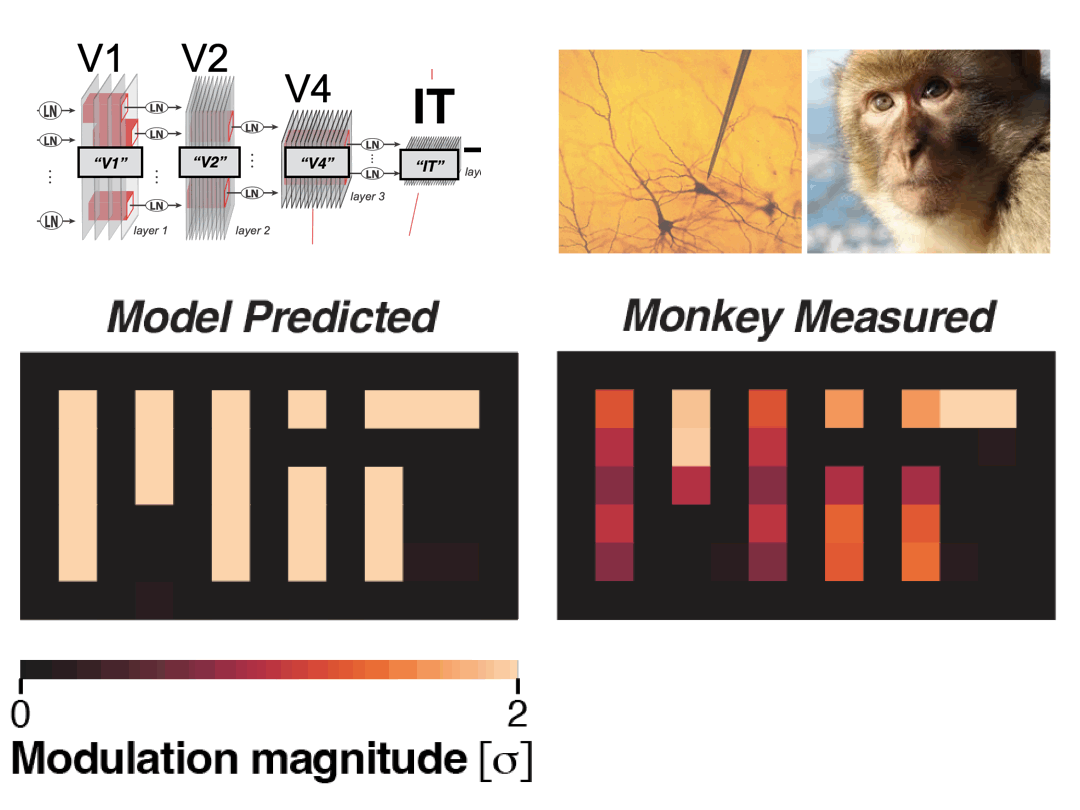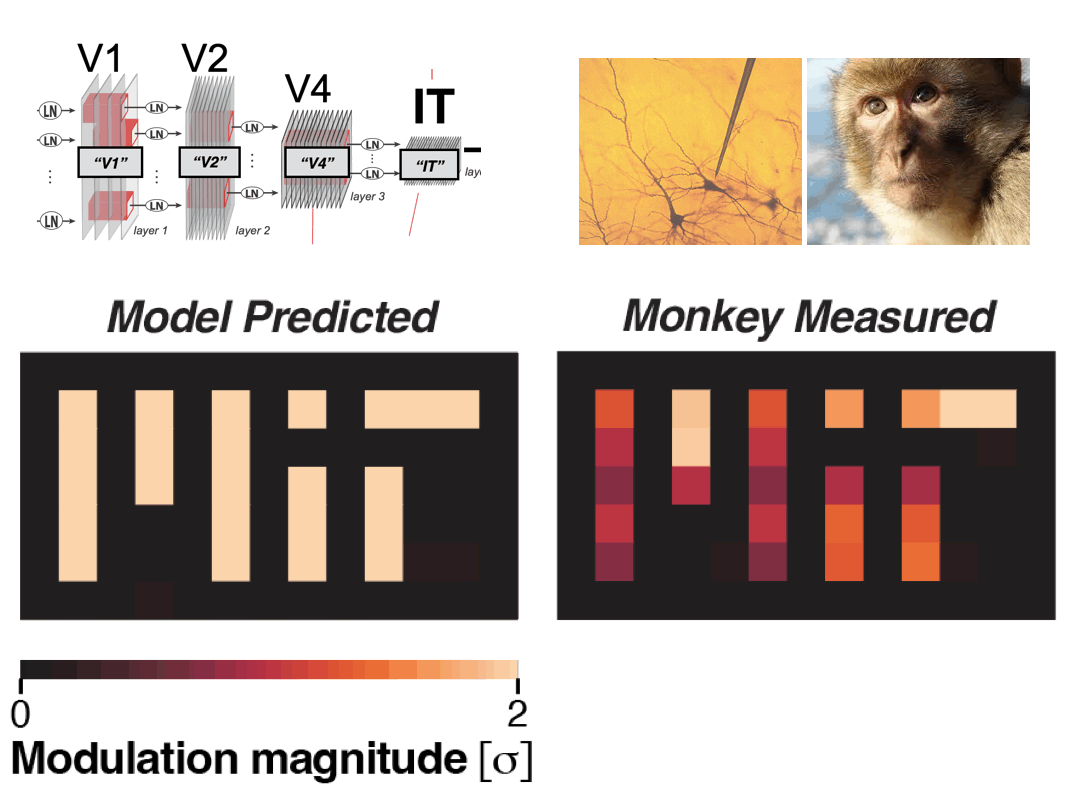
- 06/2025: Released a new preprint on directional neural modulation in IT cortex via natural vision perturbations
- 05/2025: Joined the NSF-Simons National Institute for Theory and Mathematics in Biology in Chicago as a Visiting Scholar
- 03/2025: Honored to join the course staff of the Brains, Minds & Machines Summer Course 2025
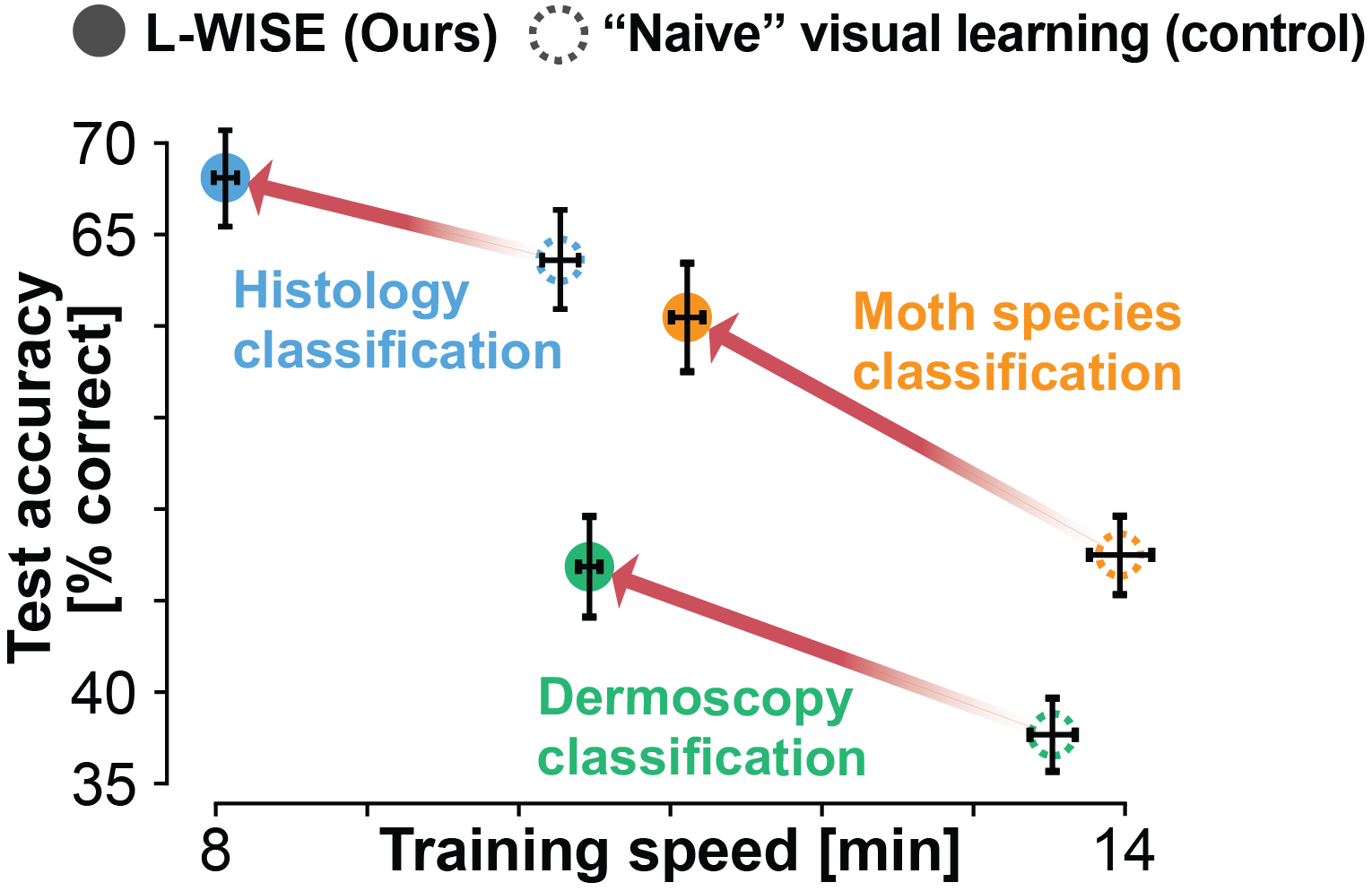
- 01/2025: Our L-WISE paper was accepted to ICLR 2025!
- 12/2024: Released a new preprint on model-guided enhancement of image category learning in humans
- 09/2023: Our Wormholes paper on perceptual modulation via robustified ANNs was accepted to NeurIPS 2023!
- 03/2023: Looking forward to teaching at the Brains, Minds & Machines Summer Course 2023
- 05/2022: Started postdoctoral training at the DiCarlo Lab at MIT!
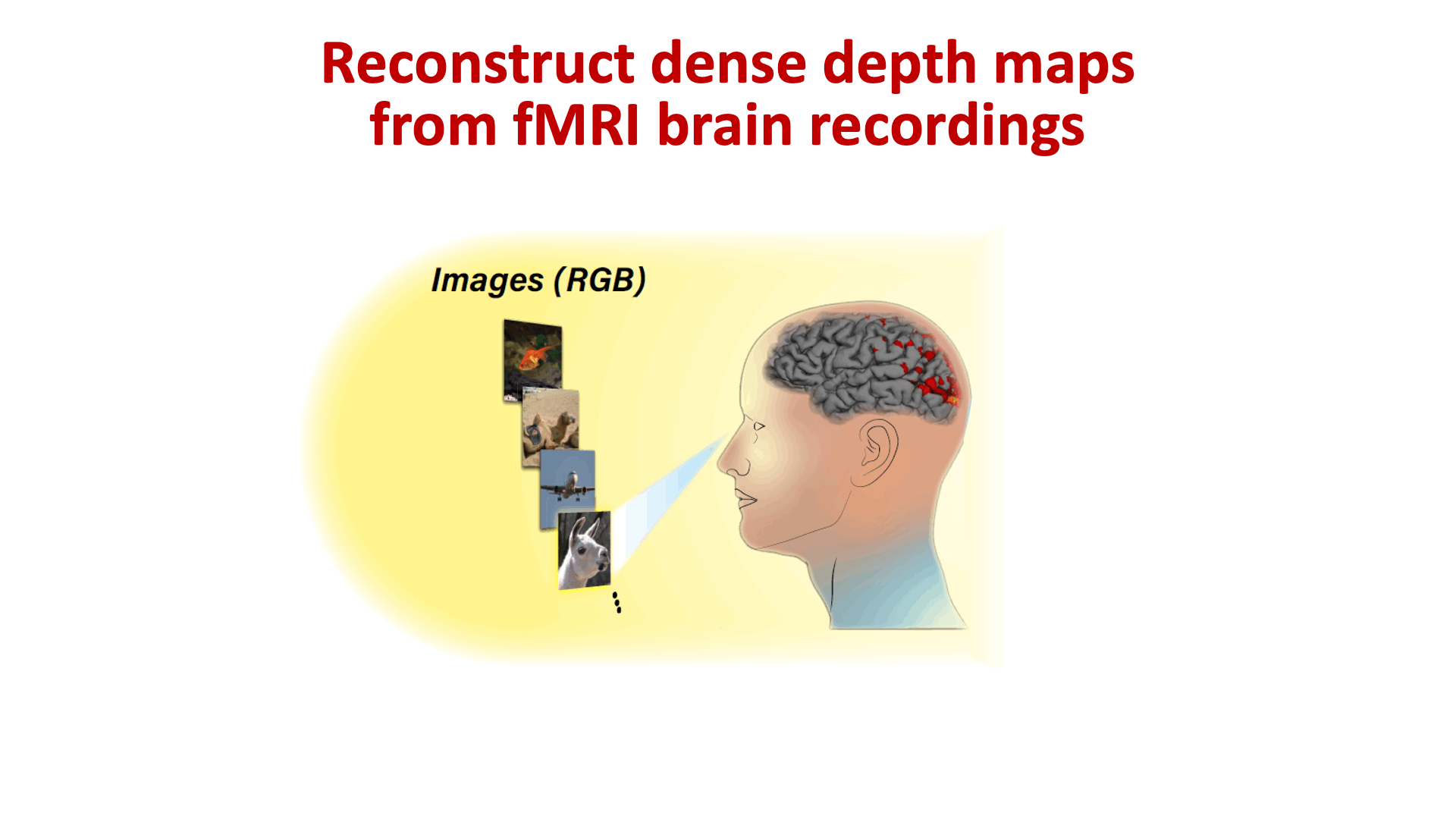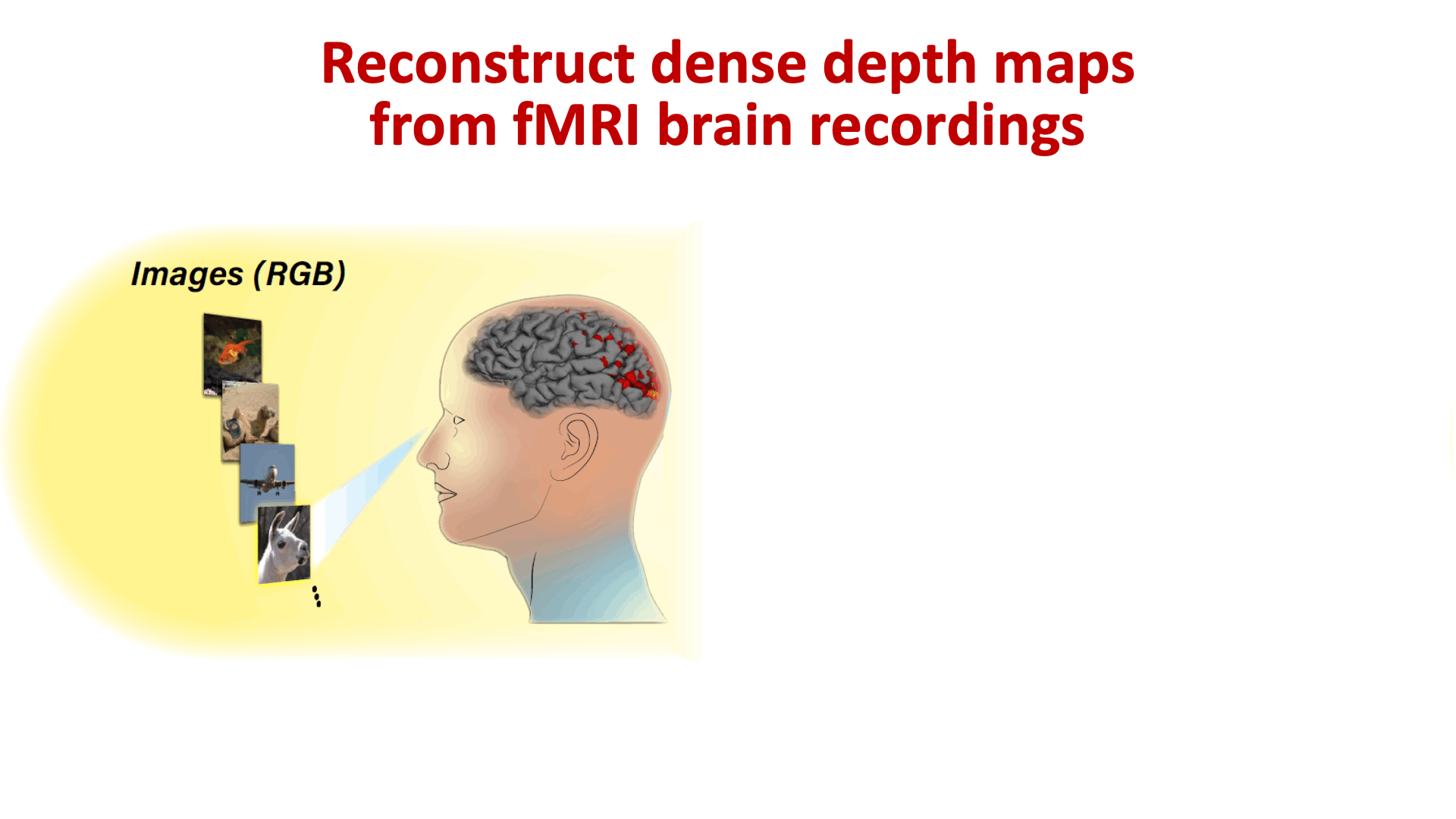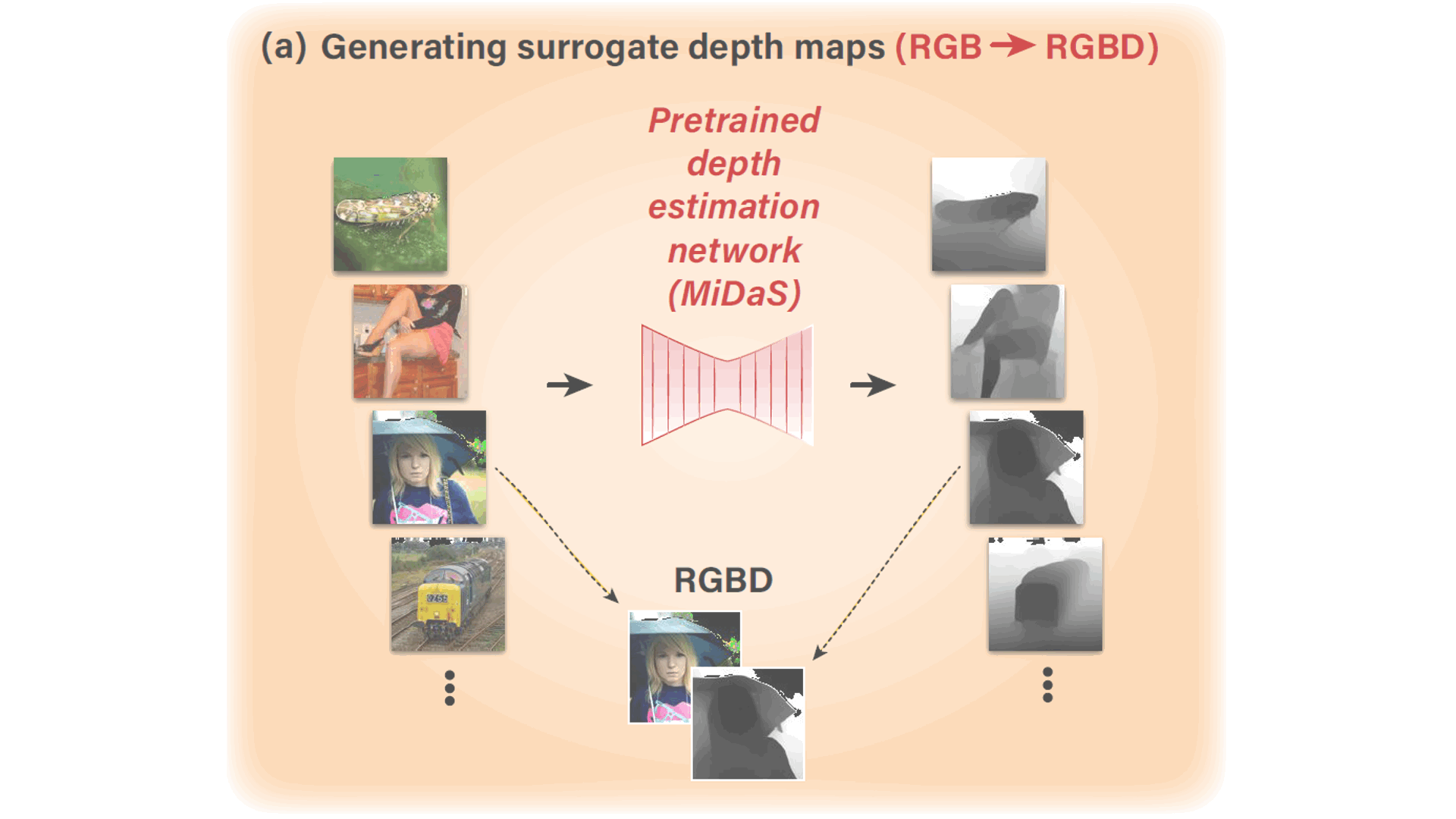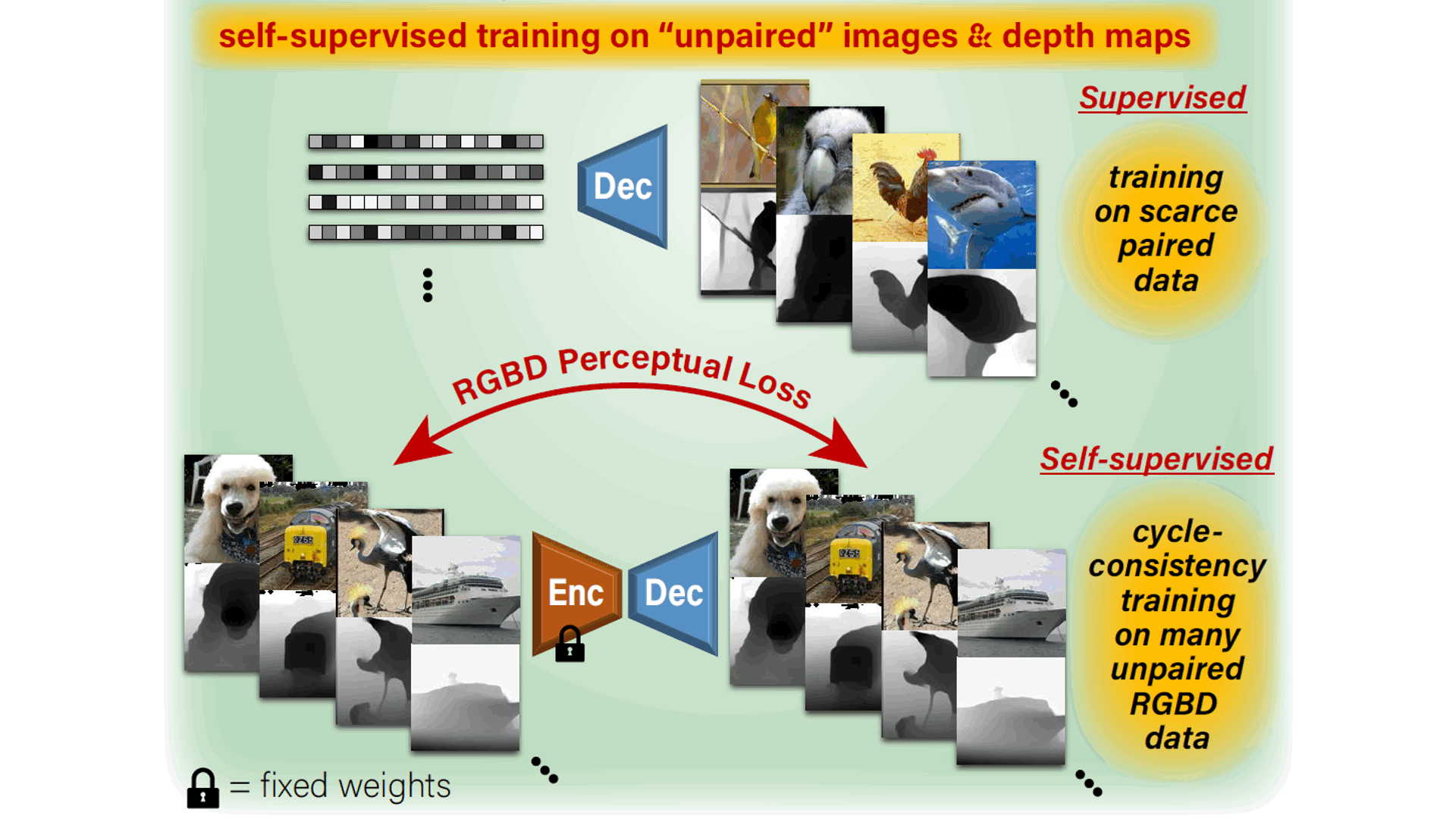
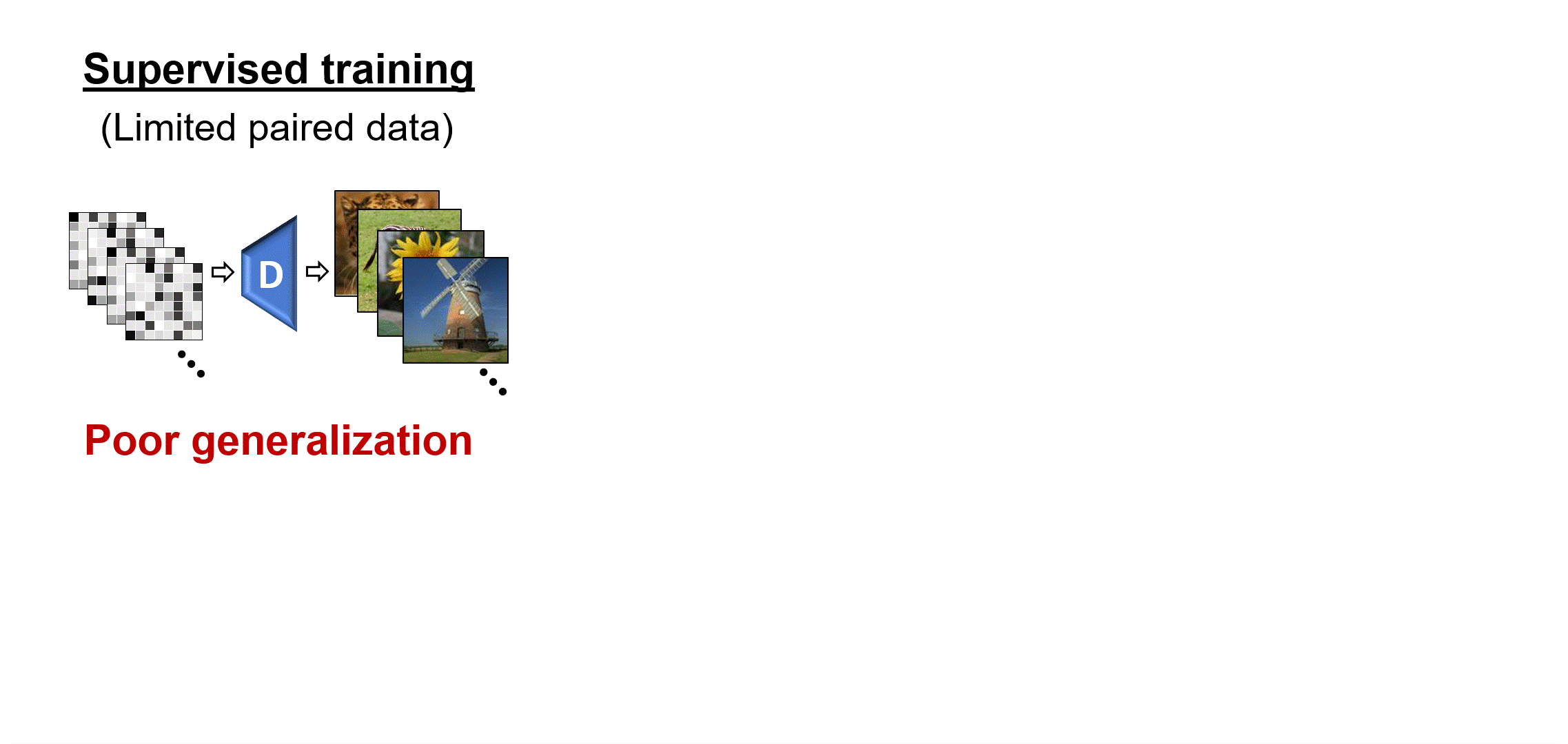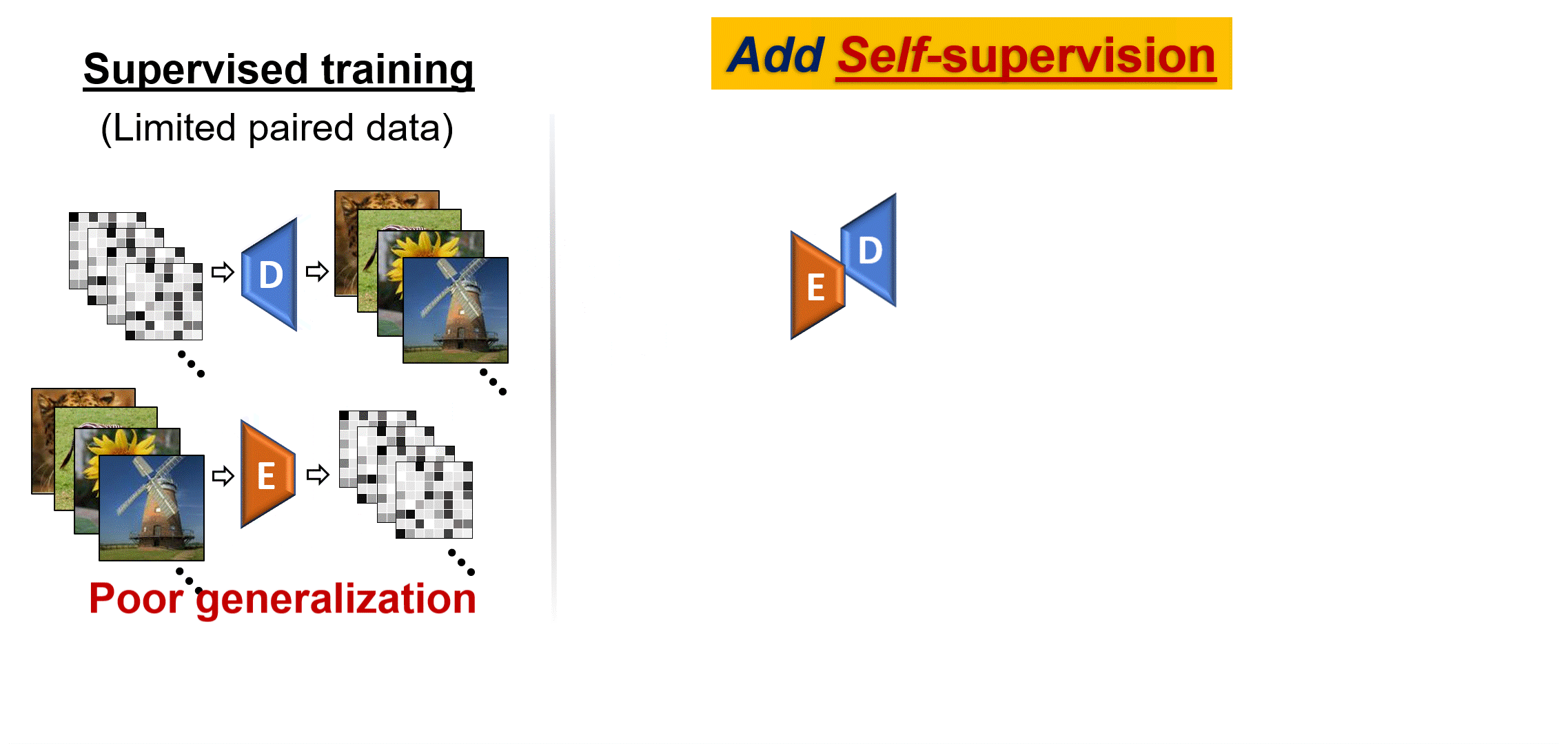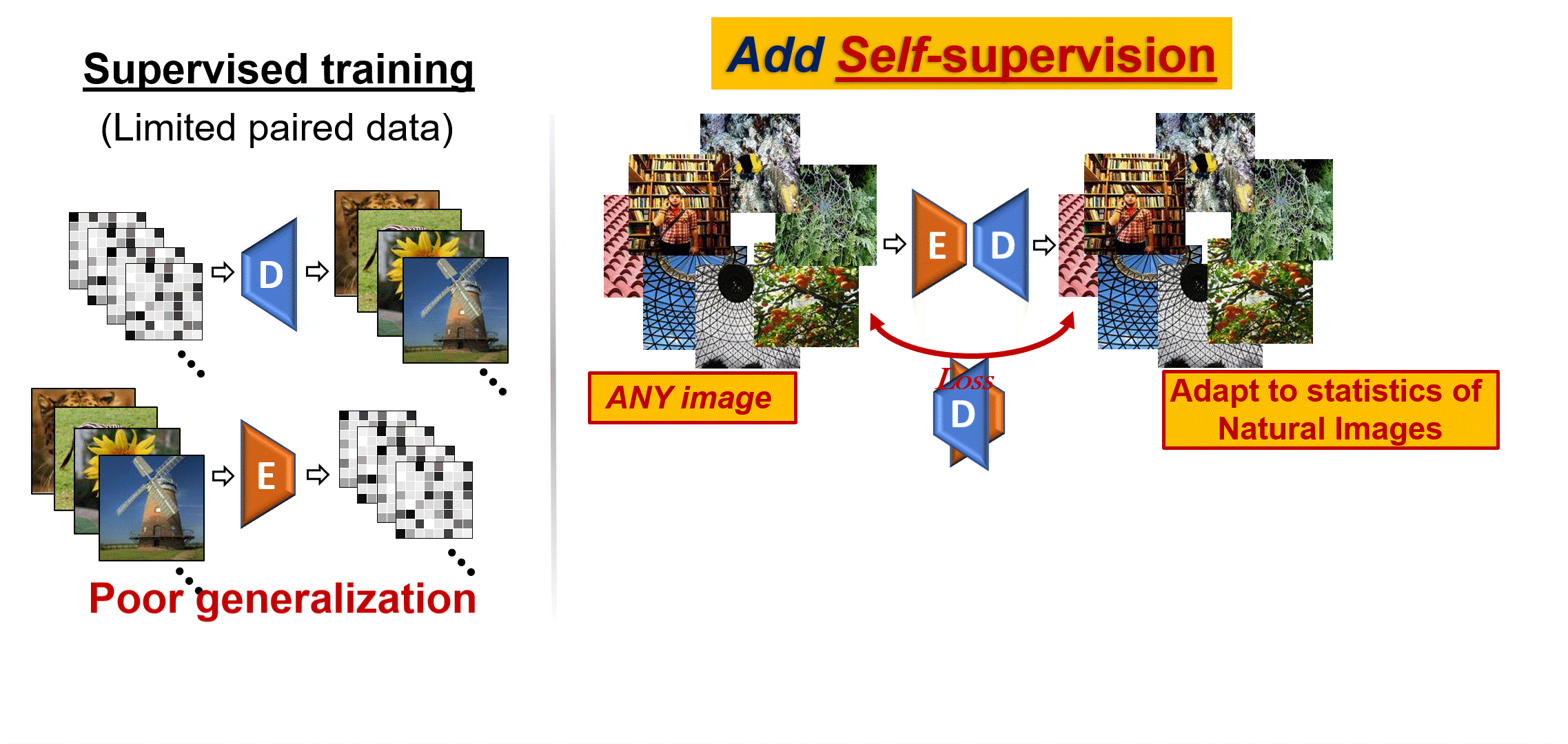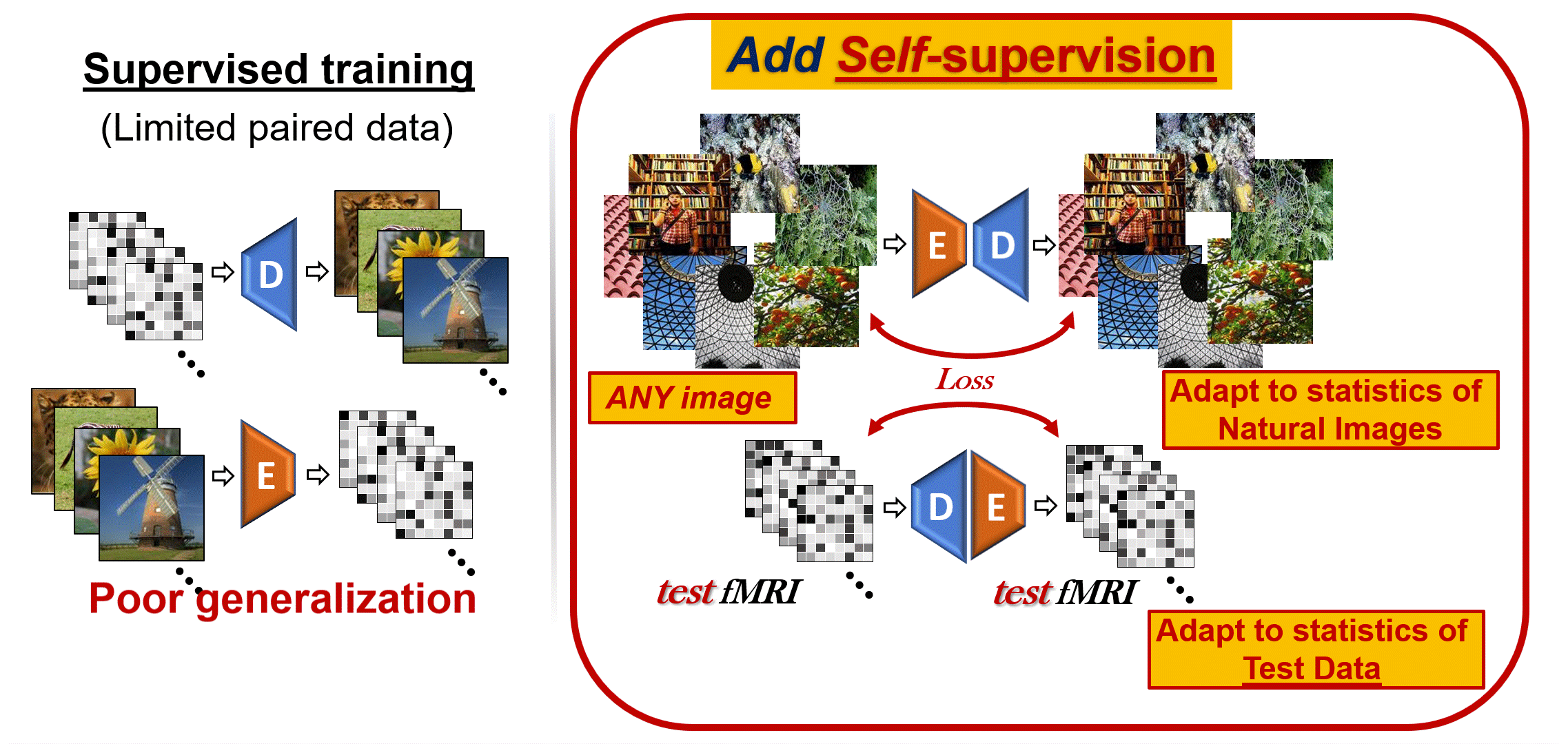
- 03/2022: Our paper on self-supervised image reconstruction and large-scale classification was published in NeuroImage
- 06/2021: New paper out on recovering 3D scene structure from brain activity
- 02/2021: Nominated for the 2021 Fulbright Postdoctoral Fellowship
- 01/2021: Successfully defended my PhD thesis: Decoding Visual Experience from Brain Activity
- 01/2020: Presented Self-Supervised Natural-Image Reconstruction from fMRI at the Israeli Computer Vision day
- 09/2019: Our paper on self-supervised image reconstruction was accepted to NeurIPS 2019
- 09/2019: Our face-space geometry paper was accepted to Nature Communications